Adventures in Ceph tuning, part 3
A second follow-up to my analysis of Ceph system tuning for Hyperconverged Infrastructure
PVC, Development, Systems Administration
Table of Contents
In 2021, I made a post about Ceph storage tuning with my my Hyperconverged Infrastructure (HCI) project PVC, and in 2022 I wrote a follow-up clarifying the test methodology with an upgraded hardware specification.
At the end of that second part, I said:
The next post in this series will look at the same performance evaluation but with NVMe SSDs, and with several even-higher OSD allocations on some newer AMD Epyc-based machines.
Well, here is that next part!
Like part 2, I’ll jump right into the cluster specifications, changes to the tests, and results. If you haven’t read parts 1 and 2 yet, I suggest you do so now to get the proper context before proceeding.
The Cluster Specs (only better)
Parts 1 and 2 used my own home server setup, based on Dell R430 servers using Broadwell-era Intel Xeon CPUs, for analysis. But being my homelab, I’m quite limited in what hardware I have access to: namely, I’m using several-generations-old hardware and SATA SSDs, so despite having some very interesting results, they are very limited by the hardware. So I wanted to get results with more modern hardware (new CPUs and NVMe SSDs). Luckily, I was able to test on just such a cluster thanks to my employer deploying my PVC solution to our customers using brand-new hardware.
Like my home cluster, these clusters use 3 nodes, with the following specifications:
| Part | node1 + node2 + node3 |
|---|---|
| Chassis | Dell R6515 |
| CPU | 1x AMD 7543P (32 core, 64 thread, 2.8 GHz base, 3.7 GHz maximum boost) |
| Memory | 128 GB DDR4 (8x 16 GB) |
| OSD DB/WAL | N/A |
| OSD Data | 1x Dell PE8010 3.84TB U.2 NVMe SSD |
| Networking | 2x BCM57416 10GbE in 802.3ad (LACP) bond |
The OSD Database Device
Because the main data disks in these servers are already NVMe, they do not feature an OSD DB/WAL device. As this made only a slight difference with the much slower SATA SSDs, I do not consider this important to use with ultra-fast NVMe OSDs.
CPU Set Layout
These tests use the same methodology as the tests in part 2, with one minor change: instead of only dedicating 2 CPU cores (plus corresponding threads) to the system, here I dedicated 4 CPU cores instead. This was done simply due to the larger core count, as this would be the counts I would run in production on these nodes.
Thus, the layout of CPU core sets on all 3 nodes looks like this:
| Slice/Processes | Allowed CPUs + Hyperthreads | Notes |
|---|---|---|
| system.slice | 0-3, 32-35 | All system processes, databases, etc. and non-OSD Ceph processes. |
| user.slice | 0-3, 32-35 | All user sessions, including FIO tasks. |
| osd.slice | 4-?, 32-? | All OSDs; how many (the ?) depends on test to find optimal number. |
| machine.slice | ?-31, ?-63 | All VMs; how many (the ?) depends on test as above. |
Due to an oversight, the primary PVC coordinator node actually flipped from node1 in tests 1 and 4-6 to node2 in tests 2 and 3, however as the results show this did not seem to make any appreciable difference in the CPU loads, and thus I think this can be ignored. I would expect this because the PVC processes running on the primary coordinator are not particularly intensive (maybe 1-2% of one core of CPU utilization).
Test Outline and Hypothesis
This test used nearly the same test outline as the previous post, only with two additional tests:
-
The first test is without any CPU limits, i.e. all cores can be used by all processes.
-
The second test is with 1 total CPU cores dedicated to OSDs (1 “per” OSD).
-
The third test is with 2 total CPU cores dedicated to OSDs (2 “per” OSD).
-
The fourth test is with 3 total CPU cores dedicated to OSDs (3 “per” OSD).
-
The fifth (new) test is with 4 total CPU cores dedicated to OSDs (4 “per” OSD).
-
The sixth (new) test is with 8 total CPU cores dedicated to OSDs (8 “per” OSD).
Since there are half as many OSDs in these nodes (i.e. only 1 each), the OSD CPU count was scaled down to match the “per” numbers with the previous post.
The fifth test was added for more details on the scaling between configurations, and the sixth was added later due to an interesting observation in the results from the first 5 tests, specifically around random write performance, that will be discussed below.
The results are still displayed as an average of 3 tests with each configuration, and include the 60-second post-test load average of all 3 nodes in addition to the raw test result to help identify trends in CPU utilization.
Similarly, our hypothesis - that more dedicated OSD CPUs is better - and open questions remain the same:
- Is doing no limit at all (pure scheduler allocations) better than any fixed limits?
- Is one of the numbers above optimal (no obvious performance hit, and diminishing returns thereafter).
Test Results
Sequential Bandwidth Read & Write
Sequential bandwidth tests tend to be “ideal situation” tests, not necessarily applicable to VM workloads except in very particular circumstances. However they can be useful for seeing the absolute maximum raw throughput performance that can be attained by the storage subsystem.
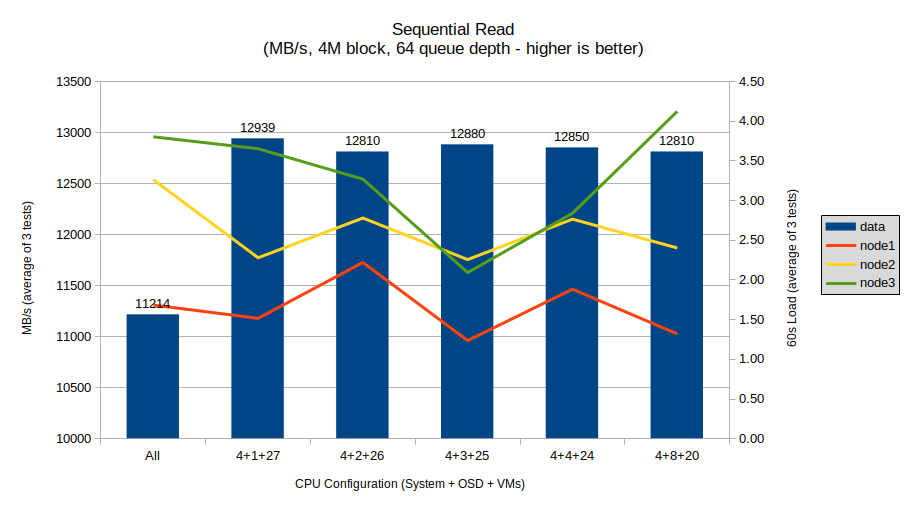
Sequential read shows a significant difference with the NVMe SSDs and newer CPUs versus the SATA SSDs in the previous post, beyond just the near doubling of speed thanks to the higher performance of the NVMe drives. In that post, no-limit sequential read was by far the highest, and this was an outlier result.
This test instead shows a result much more inline with expectations: no-limit performance is significantly lower than the dedicated limits, and by a relatively large 13% margin.
The best result was with the 4+1+27 configuration, with a decreasing stair-step pattern to the 4+4+24 configuration. However, all the limit tests were within 1% of each other, which I would consider the margin of error.
Thus, this test upholds the hypothesis: a limit is a good thing to avoid scheduler overhead, though there is no clear winner in terms of the number of dedicated OSD CPUs.
CPU load does show an interesting drop with the 4+3+25 configuration before jumping back up in the 4+4+24 configuration, however all nodes track each other, and the node with the widest swing (node3) was not a coordinator in any of the tests, so this is likely due to the VMs rather than the OSD processes.
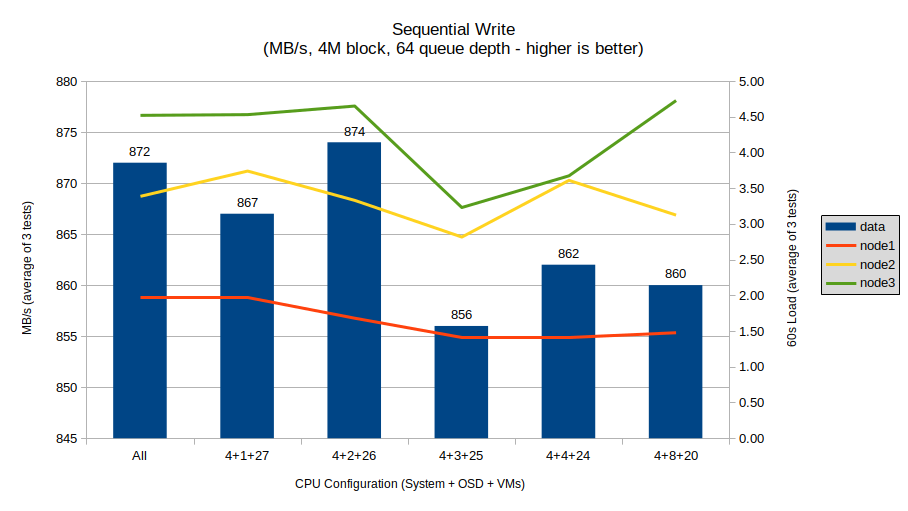
Sequential write shows a similar stair-step pattern, though more pronounced. The no-limit performance is actually the second-best here, which is an interesting result, though again the results are all within a nearly margin-of-error 2% of each other.
The highest performance was the 4+2+26, though interestingly the 4+3+25 configuration performed the worst. Though again since these are all within a reasonable margin of error, I think we can conclude that for sequential writes, there is no conclusive benefit to a CPU limit.
System load follows the same trend as did sequential reads, with a drop off for each test until a bottom with the 4+3+25 configuration before rebounding slightly higher for the 4+4+24 configuration. I’m not sure at this point if these load numbers are even showing anything at all, but it is still interesting to see.
Finally, in watching the live results, there was full saturation of the 10GbE NIC during this test:
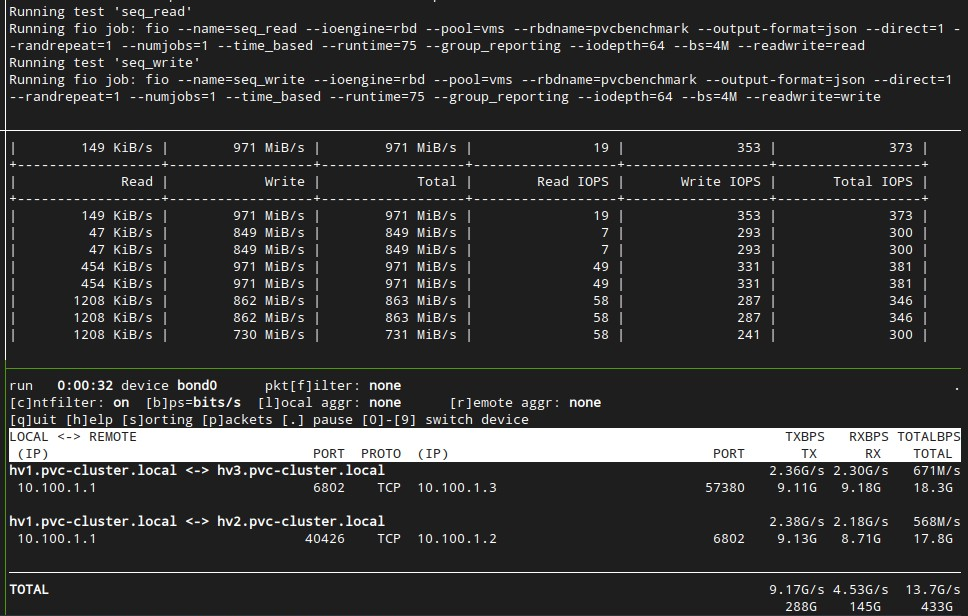
This is completely expected, since our configuration uses a copies=3 replication mode, so we should expect about 50% of the performance of the sequential reads, since every write is replicated over the network twice. It definitely proves that our limitation here is not the drives but the network, but also shows that this is not completely linear, since instead of 50% we’re actually seeing about 70% of the maximum network bandwidth in actual performance.
Random IOPS Read & Write
Random IO tests tend to better reflect the realities of VM clusters, and thus are likely the most applicable to PVC.
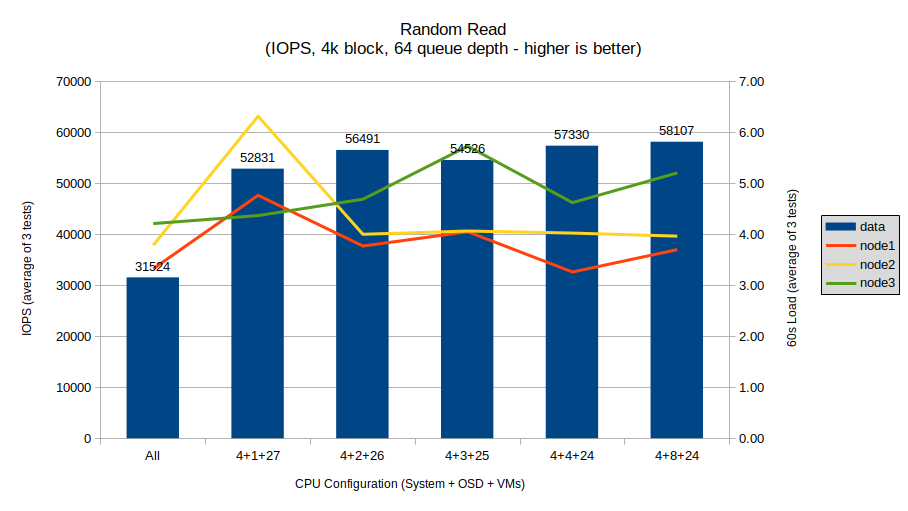
Random read shows a similar trend as sequential reads, and one completely in-line with our hypothesis. There is definitely a more pronounced trend here though, with a clear increase in performance of about 8% between the worst (4+1+27) and best (4+8+24) results.
However this test shows yet another stair-step pattern where the 4+2+26 configuration outpaced the 4+3+25 configuration. I suspect this might be due to the on-package NUMA domains and chiplet architecture of the Epyc chips, whereby the 3rd core has to traverse a higher-latency interconnect and thus hurts performance when going from 2 to 3 dedicated CPUs, though more in-depth testing would be needed to definitively confirm this.
System load continues to show almost no correlation at all with performance, and thus can be ignored.
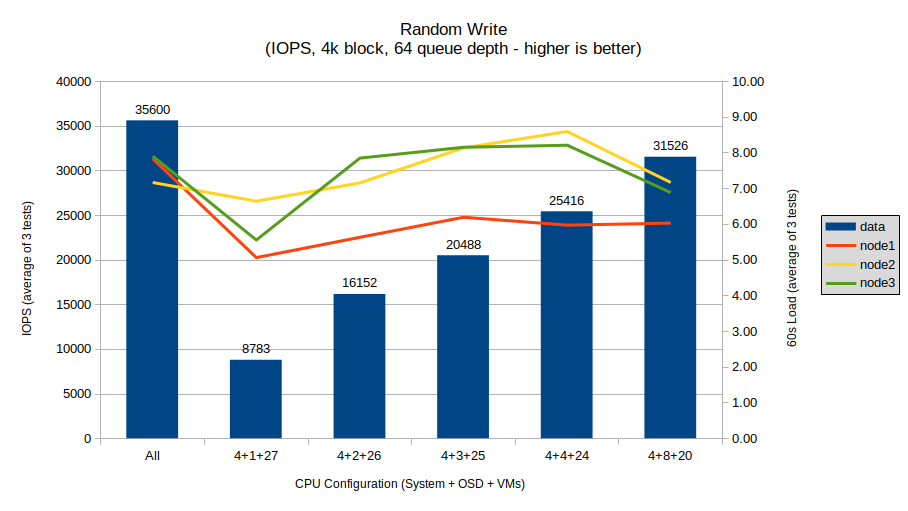
Random writes bring back the strange anomaly that we saw with sequential reads in the previous post. Namely, that for some reason, the no-limit configuration performs significantly better than all limits. After that, the performance seems to scale roughly linearly with each increase in CPU core count, exactly as was seen with the SATA SSDs in the previous post.
One possible explanation is again the NUMA domains within the CPU package. The Linux kernel is aware of these limitations, and thus could potentially be assigning CPU resources to optimize performance, especially for the CPU-to-NIC pipeline. Again this would need some more thorough, in-depth testing to confirm, but it is my hunch that this is occurring.
The system load here shows another possibly explanation for the anomalous results though. Random writes seem to hit the CPU much harder than the other tests, and the baseline load of all nodes with the no-limit configuration is about 8, which would indicate that the OSD processes want about 8 CPU cores per OSD here. Adding in the 4+8+20 configuration, we can see that this is definitely higher than all the other limit configurations, but is still less than the no-limit configuration, so this doesn’t seem to be the only explanation. It does appear that the scaling is not linear as well, since doubling the cores only brought us about half-way up to the no-limit performance, thus pointing towards the NUMA limit as well and giving us a pretty conclusively “yes” answer to our first main question.
For write-heavy workloads, this is a very important takeaway. This test clearly shows that the no-limit configuration is ideal for random writes on NVMe drives, as the Linux scheduler seems better able to distribute the load among many cores. I’d be interested to see how this is affected by many CPU-heavy noisy-neighbour VMs, but testing this is extremely difficult and thus is not in scope for this series.
95th Percentile Latency Read & Write
Latency tests show the “best case” scenarios for the time individual writes can take to complete. A lower latency means the system can service writes far quicker. With Ceph, due to the inter-node replication, latency will always be based primarily on network latency, though there are some gains to be had.
These tests are based on the 95th percentile latency numbers; thus, these are the times in which 95% of operations will have completed, ignoring the outlying 5%. Though not shown here, the actual FIO test results show a fairly consistent spread up until the 99.9th percentile, so this number was chosen as a “good average” for everyday performance.
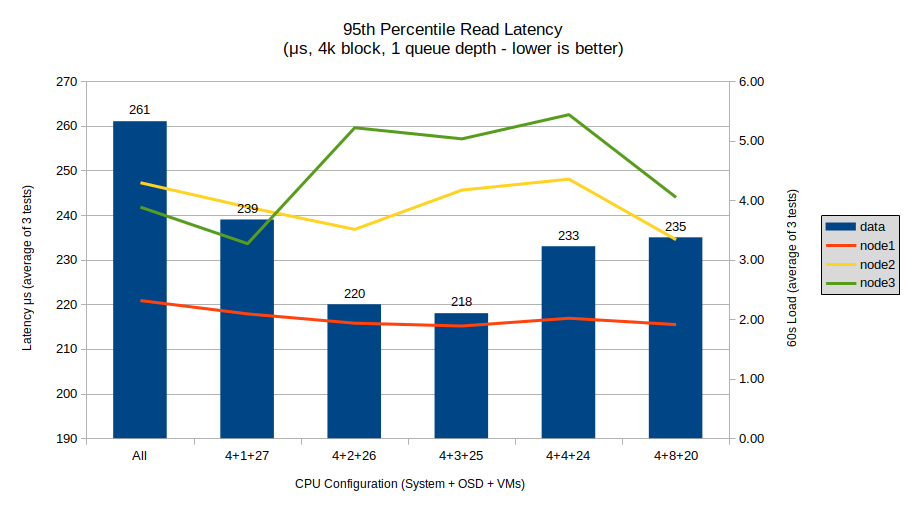
Read latency shows a consistent downwards trend throughout the configurations, though with the 4+4+24 and 4+8+24 results being outliers. However the latency here is very good, only 1/4 of the latency of the SATA SSDs in the previous post, and the results are all so low that they are not likely to be particularly impactful. We’re really pushing raw network latency and packet processing overheads with these results.
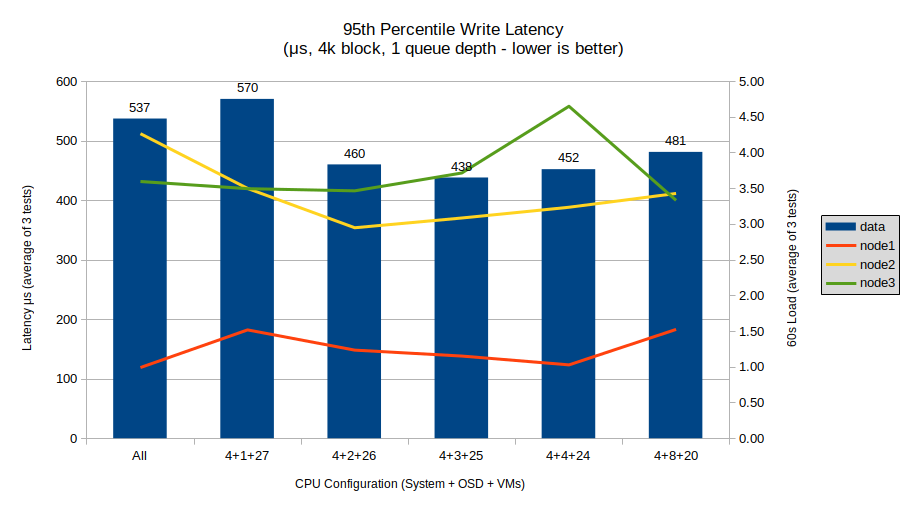
Write latency also shows a major improvement over SATA SSDs, being only 1/5 of those results. It also, like the read latency, shows a fairly limited spread in results, though with a similar uptick from 4+3+25 to 4+4+24 to 4+8+20. Like read latency, I don’t believe these numbers are significant enough to show a major benefit to the CPU limits.
Conclusions
Our results with NVMe drives shows some interesting differences from SATA SSDs. For sequential reads, the outlier result of the SATA drives is eliminated, but it is replaced instead with an outlier result for random writes, likely one of the most important metrics when talking of VM workloads. In addition the better CPUs are also likely impacting the results, and the limitations of the 10GbE networking really come into play here: I expect we might see some differences if we were running on a much faster network interconnect.
Based primarily on that one result, I think we can safely conclude that while there are some minor gains to be made with sequential read performance and some more major gains with random read performance, overall a CPU limit on the Ceph OSD processes does not seem to be worth the trade-offs for NVMe SSDs, at least in write-heavy workloads. If your workload is extremely random-read-heavy, then a limit might be beneficial, but if it is more write-heavy, CPU limits seem to hurt more than help. This is in contrast to SATA SSDs on the older processors where there were clear benefits to the CPU limit.
The final part of this series will investigate the results if we put multiple OSDs on one NVMe drive and then rerun these same tests. Stay tuned for that in the next few months!