Adventures in Ceph tuning, part 2
A follow-up to my analysis of Ceph system tuning for Hyperconverged Infrastructure
PVC, Development, Systems Administration
Table of Contents
Last year, I made a post about Ceph storage tuning with my my Hyperconverged Infrastructure (HCI) project PVC, with some interesting results. At the time, I outlined how two of the nodes were a newer, more robust server configuration, but I was still stuck with one old node which was potentially throwing off my performance results and analysis. Now, I have finally acquired a 3rd server matching the spec of the other 2, bringing all 3 of my hypervisor nodes into perfect balance. Also, earlier in the year, I upgraded the CPUs of the nodes to the Intel E5-2683 V4, which provides double the cores, threads, and L3 cache than the previous 8-core E5-2620 V4’s, helping further boost performance.

With my configuration now standardized across all the nodes, I can finally revisit the performance analysis from that post and make some more useful conclusions, without mismatched CPUs getting in the way.
If you haven’t read that previous post, I recommend doing so now to get the context, as I will be jumping right in to the updated testing and results.
The Cluster Specs
All 3 nodes in the cluster now have the following specifications:
| Part | node1 + node2 + node3 |
|---|---|
| Chassis | Dell R430 |
| CPU | 1x Intel E5-2683 v4 (16 core, 32 thread, 2.1 GHz base, 3.0 GHz maximum boost) |
| Memory | 128 GB DDR4 (4x 32 GB) |
| OSD DB/WAL (NVMe) | 1x Intel DC P4801X 100 GB |
| OSD Data (SATA) | 2x Intel DC S3700 800 GB |
| Networking | 2x 10GbE in 802.3ad (LACP) bond |
The OSD Database Device
As part of that original round of testing, I compared various configurations, including no WAL, with WAL, and various CPU set configurations with no WAL. After that testing was completed, the slight gains of the WAL prompted me to leave that configuration in place for production going forward, and I don’t see much reason to remove it for further testing, due to the clear benefit (even if slight) that it gave to write performance with my fairly-slow-by-modern-standards SATA data SSDs. Thus, this follow-up post will focus exclusively on the CPU set configurations with the upgraded and balanced CPUs.
The Fatal Flaw of my Previous Tests and Updated CPU Set Configuration
The CPU-limited tests as outlined in the original post were fatally flawed. While I was indeed able to use CPU sets with the cset tool to limit the OSD processes to specific cores, and this appeared to work, the problem was that I wasn’t limiting anything else to the non-OSD CPU cores. Thus, the OSDs were likely being thrashed by the various other processes in addition to being limited to specific CPUs. This might explain some of the strange anomalies in performance that are visible in those tests.
To counteract this, I created a fresh, from-scratch CPU tuning mechanism for the PVC Ansible deployment scheme. With this new mechanism, CPUs are limited with the systemd AllowedCPUs and CPUAffinity flags, which are set on the various specific systemd slices that the system uses to organize processes, including a custom OSD slice. This ensures that the limit happens in both directions and everything is forced into its own proper CPU set.
In addition to separating the OSDs and VMs, a third CPU set is also added strictly for system processes. This is capped at 2 cores (plus hyperthreads) for all testing here, and the FIO processes are also limited to this CPU set.
Thus, the final layout of CPU core sets on all 3 nodes looks like this:
| Slice/Processes | Allowed CPUs + Hyperthreads | Notes |
|---|---|---|
| system.slice | 0-1, 16-17 | All system processes, databases, etc. and non-OSD Ceph processes. |
| user.slice | 0-1, 16-17 | All user sessions, including FIO tasks. |
| osd.slice | 2-?, 18-? | All OSDs; how many (the ?) depends on test to find optimal number. |
| machine.slice | ?-15, ?-31 | All VMs; how many (the ?) depends on test as above. |
The previous tests were also, as mentioned above, significantly limited by the low CPU core counts of the old processors, and during those tests the node running the tests was flushed of VMs; the new CPUs allow both flaws to be corrected, and all 3 nodes will have VMs present, with the primary node running the OSD tests in the user.slice CPU set.
During all tests, node1 was both the testing node, as well as primary PVC coordinator (adding a slightly higher process burden to it).
Test Outline and Hypothesis
To determine both whether limiting OSD CPUs, and if so, how many, is worthwhile, a set of 4 total tests was run.
-
The first test is without any CPU limits, i.e. all cores can be used by all processes.
-
The second test is with 2 total CPU cores dedicated to OSDs (1 “per” OSD).
-
The third test is with 4 total CPU cores dedicated to OSDs (2 “per” OSD).
-
The fourth test is with 6 total CPU cores dedicated to OSDs (3 “per” OSD).
The results are displayed as an average of 3 tests with each configuration, and include the 60-second post-test load average of all 3 nodes in addition to the raw test result to help identify trends in CPU utilization.
I would expect, with Ceph’s CPU-bound nature, that each increase in the number of CPU cores dedicated to OSDs will increase performance. The two open questions are thus:
- Is doing no limit at all (pure scheduler allocations) better than any fixed limits?
- Is one of the numbers above optimal (no obvious performance hit, and diminishing returns thereafter).
Test Results
Sequential Bandwidth Read & Write
Sequential bandwidth tests tend to be “ideal situation” tests, not necessarily applicable to VM workloads except in very particular circumstances. However they can be useful for seeing the absolute maximum raw throughput performance that can be attained by the storage subsystem.
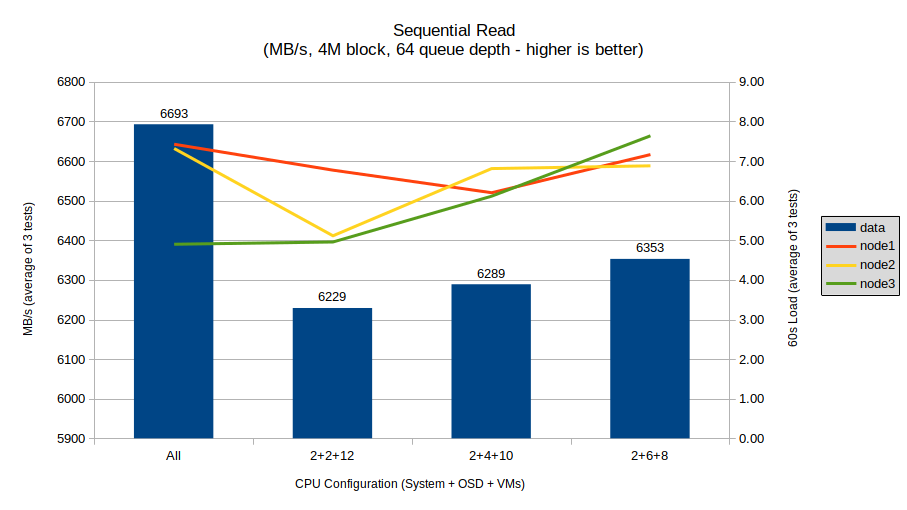
Sequential read shows a significant spike with the all-cores configuration, then a much more consistent performance curve in the limited configurations. There is a significant difference in performance between the configurations, with a margin of just over 450 MB/s between the best (all-cores) and worst (2+2+12) configurations.
The most interesting point to note is that the all-cores configuration has significantly higher sequential read performance than any limited configuration, and in such a way that even following the pattern of the limited configurations we would not reach this high performance even with all 16 cores dedicated. The Linux scheduler must be working some magic to ensure the raw data can transfer very quickly in the all-cores configuration.
System load also follows an interesting trend. The highest load on nodes 1 and 2, and the lowest on node 3, was with the all-cores configuration, indicating that Ceph OSDs will indeed use many CPU cores to spread read load around. The overall load became much more balanced with the 2+4+10 and 2+6+8 configurations.
This is overall an interesting result and, as will be shown below, the outlier in terms of all-core configuration performance. It does not adhere to the hypothesis, and provides a “yes” answer for the first question (thus negating the second).
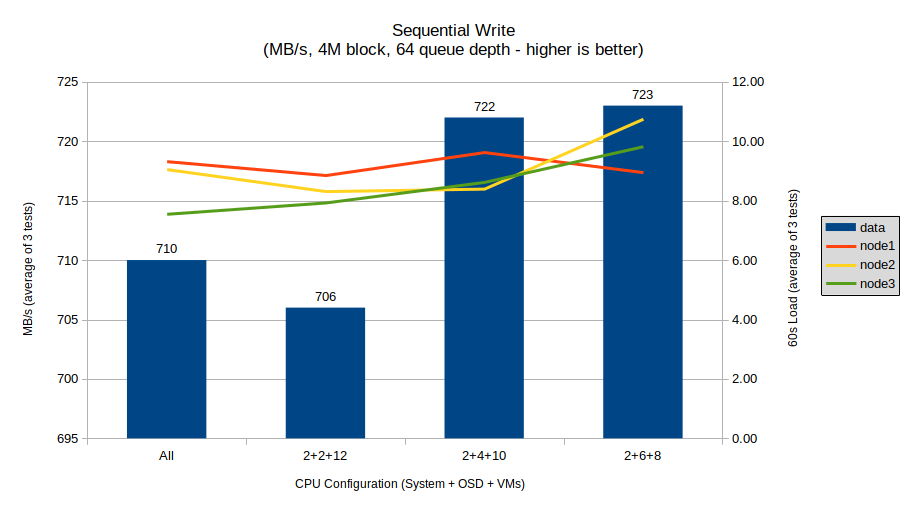
Sequential write shows a much more consistent result in line with the hypothesis above, and providing a clear “no” answer for the first question and a fairly clear point of diminishing returns for the second. The overall margin between the configurations is minimal, with just 17 MB/s of performance difference between the best (2+6+8) and worst (2+2+12) configurations.
There is a clear drop going from the all-cores configuration to the 2+2+12 configuration, however performance immediately spikes to even higher levels with the 2+4+10 and 2+6+8 configurations, with those only showing a 1 MB/s difference between them. This points towards the 2+4+10 configuration as an optimal one for sequential write performance, as it leaves more cores for VMs and shows that OSD processes seem to use at most about 2 cores each for sequential write operations. The performance spread does however limit the applicability of this test to much higher-throughput devices (i.e. NVMe SSDs), leaving the question still somewhat open.
System load also follows a general upwards trend, indicating better overall CPU utilization.
Random IOPS Read & Write
Random IO tests tend to better reflect the realities of VM clusters, and thus are likely the most applicable to PVC.
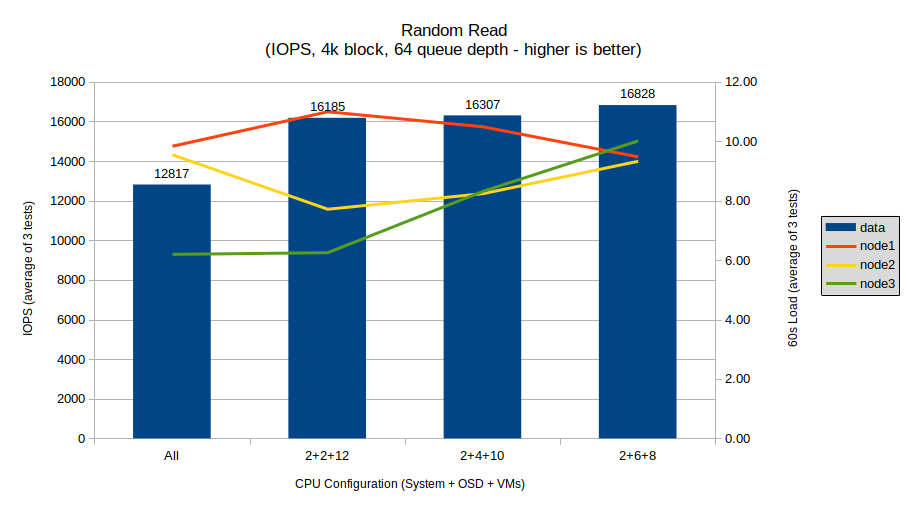
Random read, like sequential write above, shows a fairly consistent upward trend in line with the the original hypothesis, as well as clear answers to the two questions (“no”, and “any limit”). The spread here is quite significant, with the difference between the best (2+6+8) and worst (all-cores) configurations being over 4100 IOs per second; this can be quite significant when speaking of many dozens of VMs doing random data operations in parallel.
This test shows the all-cores configuration as the clear loser, with a very significant performance benefit to even the most modest (2+2+12) limited configuration. Beyond that, the difference between 2 OSD cores and 6 OSD cores is a relatively small 643 IOs per second; still significant, but not nearly as much as the nearly 3500 IOs per second uplift between the all-cores and 2+2+12 configurations.
This test definitely points towards a trade-off between VM CPU allocations and maximum read performance, but also seems to indicate that, unlike sequential reads, Ceph does far better with just a few dedicated cores versus many shared cores when performing random reads.
System load follows a similar result to the sequential read tests, with more significant load on the testing node for the all-core and 2+2+12 configurations, before balancing out more in the 2+6+8 configuration.
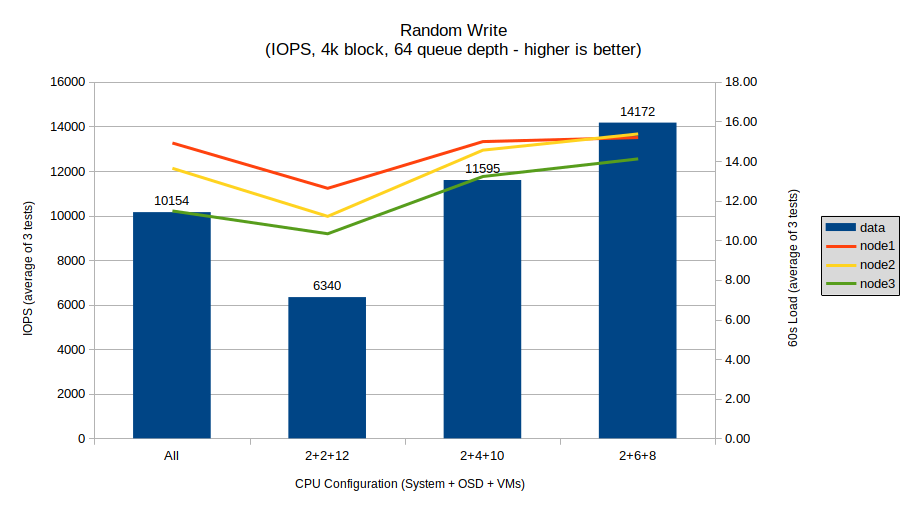
Random write again continues a general trend in line with the hypothesis and providing nearly the same answers as the sequential write tests, with a similar precipitous drop for the 2+2+12 configuration versus the all-core configuration, before rebounding and increasing with the 2+4+10 and 2+6+8 configurations. The overall margin is a very significant 7832 IOs per second between the worst (2+2+12) and best (2+6+8) tests, more than double the performance.
This test definitely shows that Ceph random writes can consume many CPU cores per OSD process, and that providing more, dedicated cores can provide significant uplift in random write performance. Thus, like random reads, there is a definite trade-off between the CPU and storage performance requirements of VMs, so a balance must be struck. With regards to the second question, this test does show less clear diminishing returns as the number of dedicated cores increases, potentially indicating that it can scale almost indefinitely.
System load shows an interesting trend compared to the other tests. Overall, the load remains in a fairly consistent spread between all 3 nodes, though with a closing gap by the 2+6+8 configuration. Of note is that the overall load drops significantly on all nodes for the 2+2+12 configuration, showing quite clearly that the OSD processes are starved for CPU resources during those tests and explaining the overall poor performance there.
95th Percentile Latency Read & Write
Latency tests show the “best case” scenarios for the time individual writes can take to complete. A lower latency means the system can service writes far quicker. With Ceph, due to the inter-node replication, latency will always be based primarily on network latency, though there are some gains to be had.
These tests are based on the 95th percentile latency numbers; thus, these are the times in which 95% of operations will have completed, ignoring the outlying 5%. Though not shown here, the actual FIO test results show a fairly consistent spread up until the 99.9th percentile, so this number was chosen as a “good average” for everyday performance.
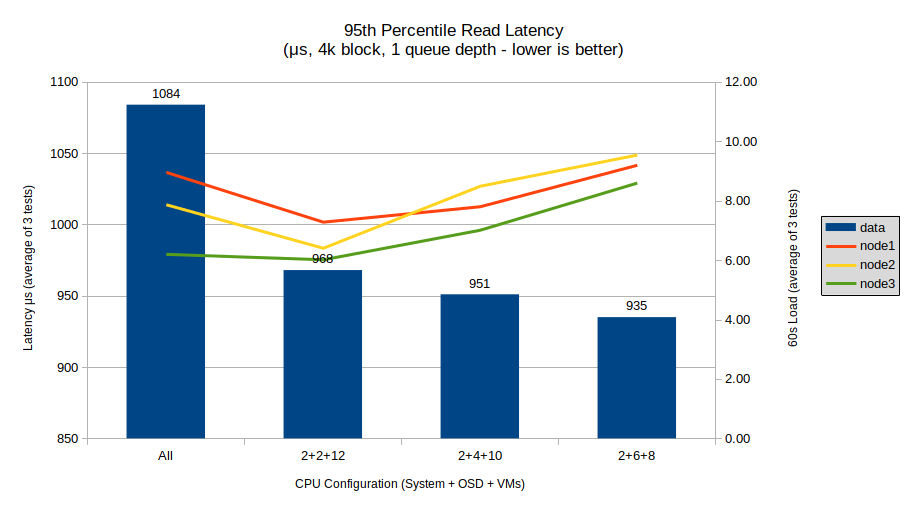
Read latency shows a consistent downwards trend like most of the tests so far, with a relatively large drop from the all-cores configuration to the 2+2+12 limited configuration, followed by steady decreases through each subsequent increase in cores. This does seem to indicate a clear benefit towards limiting CPUs, though like the random read tests, the point of diminishing returns comes fairly quickly.
System load also follows another hockey-stick-converging pattern, showing that CPU utilization is definitely correlated with the lower latency as the number of dedicated cores increases.
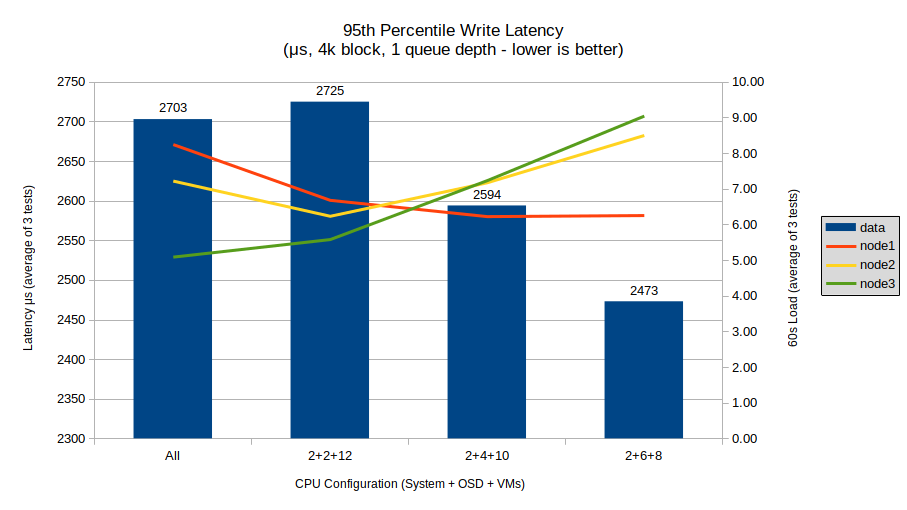
Write latency shows another result consistent with the other write tests, where the 2+2+12 configuration fares (slightly) worse than the all-cores configuration before rebounding. Here the latency difference becomes significant, with the spread of 252 μs being enough to become noticeable in high-performance applications. There is also no clear point of diminishing returns, just like the other write tests.
System load follows a very curious curve, with node1 load dropping off and levelling out with the 2+4+10 and 2+6+8 configurations, while the other nodes continue to increase. I’m not sure exactly what to make of this result, but the overall performance trend does seem to indicate that, like other write tests, more cores dedicated to the OSDs results in higher utilization and performance.
Conclusions
With a valid testing methodology, I believe we can demonstrate some clear takeaways from this testing.
First, our original hypothesis that “more cores means better performance” certainly holds. Ceph is absolutely CPU-bound, and better (newer) CPUs at higher frequencies with more cores are always a benefit to a hyperconverged cluster system like PVC. It also clearly shows that Ceph OSD processes are not single-threaded in the latest versions, and that they can utilize many cores to benefit performance.
Second, our first unanswered question, “is a limit worthwhile over no limit”, seems to be a definitive “yes” in all except for one case: sequential reads. Only in that situation was the all-cores configuration able to beat all other configurations. However, given that sequential read performance is, generally, a purely artificial benchmark, and also not particularly applicable to the PVC workload, I would say that it is definitely the case that a dedicated set of CPUs for the OSDs is a good best-practice to follow, as the results from all other tests do show a clear benefit.
Third, our second unanswered question, “how many dedicated cores should OSDs be given and what are the diminishing return points”, is less clear cut. From the testing results, it is clear that only 1 core per OSD process is definitely too few, as this configuration always performed the worst out of the 3 tested. Beyond that, the workload on the cluster, and the balance between cores-for-VMs and storage performance, become more important. It is clear from the results that a read-heavy cluster would benefit most from a 2-cores-per-OSD configuration, as beyond that the returns seem to diminish quickly. For write-heavy clusters, though, more cores seem to provide an obvious benefit scaling up at least past our 2+6+8 configuration, and thus such clusters should be built with as many cores as possible and then with at least 3-4 (or more) cores dedicated to each OSD process.
The overall takeaway is thus: I will begin implementing some sort of CPU core affinity configuration on all new PVC clusters, and retrofit one befitting the required performance to all existing clusters; the benefits clearly outweigh the drawbacks.
The next post in this series will look at the same performance evaluation but with NVMe SSDs, and with several even-higher OSD allocations on some newer AMD Epyc-based machines. Stay tuned for more!